计算语言学是中国传媒大学语言信息处理类博士研究生招生考试的核心专业科目,其真题对把握文本数据中热词挖掘的方法逻辑具有关键指导意义。考生可通过以下权威渠道获取该校全学科考博真题(含计算语言学、各专业课等)及配套高分答案详解,为备考提供精准资源支撑:
- 考博信息网官网:http://www.kaoboinfo.com/
- 中国传媒大学历年考博真题下载专用页面:http://www.kaoboinfo.com/shijuan/school/408061_1_1233366.html
中国传媒大学计算语言学考博真题覆盖多年份,所有年份真题均配备完整、精准的高分答案详解,解析由计算语言学专业教研团队编写,涵盖考点定位、方法设计、结果验证及应用价值,能帮助考生高效掌握命题规律与应试策略。以下为中国传媒大学计算语言学考博真题(精选题目)及答案详解,助力考生针对性备考。
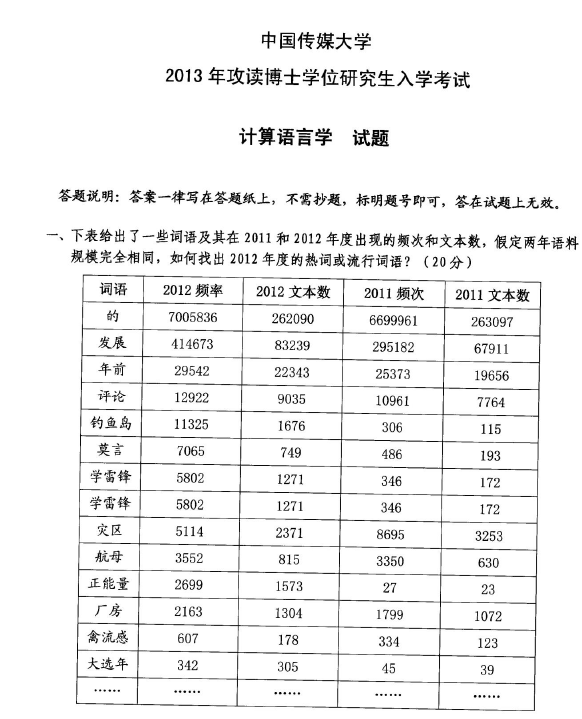
一、下表给出了一些词语及其在 2011 和 2012 年度出现的频次和文本数。假定两年语料规模完全相同,如何找出 2012 年度的热词或流行词语?(20 分)
考点定位:本题考查文本数据中热词挖掘的量化方法,聚焦 “跨年度词语流行度变化” 的分析逻辑,是计算语言学学科中文本挖掘研究的重点考点。
在语料规模相同的前提下,可通过 “频率变化率”“文本覆盖率变化” 等量化指标,结合语义特征筛选 2012 年度热词:
- 核心分析指标设计
-
频率相对变化率:
计算词语 2012 年与 2011 年的频率比值(记为
\(R_f = \frac{2012频率}{2011频次}\)),比值越大,说明词语使用热度增长越显著。
例:“正能量” 的
\(R_f = \frac{2699}{27} ≈ 99.96\),“钓鱼岛” 的
\(R_f = \frac{11325}{306} ≈ 37.01\)。
-
文本覆盖率变化:
文本覆盖率 = 词语出现的文本数 / 总文本数(因语料规模相同,总文本数固定,可直接比较 “文本数比值”
\(R_t = \frac{2012文本数}{2011文本数}\)),比值越大,说明词语的传播范围扩张越明显。
例:“正能量” 的
\(R_t = \frac{1573}{23} ≈ 68.39\),“莫言” 的
\(R_t = \frac{749}{193} ≈ 3.88\)。
- 热词筛选步骤
-
第一步:排除高频常用词:
如 “的” 是通用虚词,虽频率高,但年度变化小(
\(R_f ≈ 1.04\)),不属于年度热词,需先过滤这类基础功能词。
-
第二步:筛选高增长词语:
选取
\(R_f\)和
\(R_t\)均显著大于 1 的词语(通常阈值设为
\(R_f ≥ 5\)且
\(R_t ≥ 3\))。
例:“正能量”“钓鱼岛”“莫言”“学雷锋”“大逃年” 均满足此条件。
-
第三步:结合语义特征验证:
热词通常对应年度热点事件(如 “钓鱼岛” 对应 2012 年领土争议事件,“莫言” 对应 2012 年诺贝尔文学奖),需结合语义背景排除无实际热点关联的高增长词(如无特殊背景的 “大逃年” 需进一步验证)。
- 2012 年度热词结果
结合指标与语义,2012 年度热词包括:钓鱼岛、莫言、正能量、学雷锋。
学术扩展:
热词挖掘是计算语言学中文本舆情分析的核心任务之一,实际应用中还需结合 “TF-IDF”“互信息” 等特征,或引入机器学习模型(如 LDA 主题模型)关联词语与年度主题。在当代研究中,如何结合社交媒体短文本的非正式语言特征优化热词挖掘,是学者们关注的热点。同时,该方法也为舆情监测、文化传播分析提供了技术支撑,体现了计算语言学学科的应用价值。
考博备考需依托权威真题资源,中国传媒大学计算语言学考博真题及全学科考博资料(含各专业课)均配备高分答案详解,可通过以下渠道获取:
- 考博信息网官网:http://www.kaoboinfo.com/
- 中国传媒大学历年考博真题下载专用页面:http://www.kaoboinfo.com/shijuan/school/408061_1_1233366.html
建议考生结合真题及答案详解系统备考,重点掌握 “文本挖掘的量化指标设计”“数据与语义的关联分析”“学术前沿追踪” 三大能力,同时关注本学科前沿研究(如预训练语言模型在热词挖掘中的应用、跨语言热词对齐技术等),提升学术表达与问题解决能力,预祝各位考生考博成功!
 您现在的位置:
您现在的位置: 